
微信小程序国密算法SM3碰撞原理揭秘
2021.3.10
2021年2月,蜚语安全在对客户产品进行安全代码审计时,发现其依赖的微信小程序sm-crypto 开源NodeJS国密算法库中的SM3算法实现(该算法库使用NodeJS对国密算法中的SM2,SM3和SM4三个算法进行了实现,并封装成接口提供给开发者使用。该国密算法库的具体实现在GitHub上开源:https://github.com/wechat-miniprogram/sm-crypto,其中sm3的实现在文件src/sm3/index.js中,微信小程序官方的参考文档链接为 https://developers.weixin.qq.com/miniprogram/dev/extended/utils/sm-crypto.html )存在重大的实现错误,导致不同的输入可被编码为相同的bitstring,进而进行SM3计算后产生“伪”hash碰撞效果。
影响
该问题影响sm-crypto的0.2.2及之前版本。由于该国密库为微信小程序官方提供的国密库,因此使用该库的都会受该碰撞的影响。根据GitHub上的信息,我们发现该作者的另一个NodeJS的库sm-crypto(https://github.com/JuneAndGreen/sm-crypto)也受该问题的影响。
根据GitHub上代码的dependent信息,光GitHub上就有260个开源项目依赖该微信小程序的国密算法库,57个项目依赖该作者NodeJS的sm-crypto库,而通过npm安装使用的sm-crypto和miniprogram-sm-crypto的开发者和项目则可能更多。问题分析
该SM3碰撞问题来源于sm3算法的实现文件src/sm3/index.js中。该SM3算法直接接收字符串作为输入,并通过以下函数将字符串转成二进制流:
const binary = str2binary(str)再进行后续的填充以及SM3的变换等。而str2binary函数的具体实现如下:
function str2binary(str) {
let binary = ''
for (let i = 0, len = str.length; i < len; i++) {
const ch = str[i]
binary += leftPad(ch.codePointAt(0).toString(2), 8)
}
return binary
}该函数使用codePointAt函数对字符串中的每一个字符,获取其编码点值,并通过toString(2)转成二进制形式后,再使用自己实现的leftPad函数对二进制串进行高位补0的操作,leftPad函数实现如下:
function leftPad(input, num) {
if (input.length >= num) return input
return (new Array(num - input.length + 1)).join('0') + input
}可以看到,leftPad的逻辑是:如果input的长度大于等于num,则直接返回,否则根据num的值对input的高位补0。我们注意到在str2binary函数中,调用leftPad函数时,num参数被设置为8。所以当传入的input的二进制长度是低于8比特的时候,是没有问题的,但是一旦input长度大于8,则leftPad函数就不会对其高位补0,而是直接返回。而我们知道所有的中文字符码点值都是超过1字节、也就是8比特的,因此中文字符在转成二进制形式后,并没有高位补0。一旦有这些中文字符在字符串中被拼接后,会导致最终进行SM3计算的二进制数据很可能不是8比特对齐的!
Proof-of-Concept
由于在这个转换过程中,没有对超过1字节字符的二进制表示进行8比特对齐,导致我们只要精心构造,就可能找到两个不同的字符串,使得这两个字符串在转换后最终得到相同的二进制表示。例如8个16比特的字符(UTF-16编码),如果最高比特位都为0,则通过该算法库中实现的二进制转换函数最终得到的二进制串是8*15=120比特,而这120比特的二进制串,同时也可以表示成多种形式,例如7个16比特的字符(最高比特位是1)拼上任意一个8比特的字符,或6个16比特的字符(最高比特位是1)拼上任意2个8比特的字符等,总共有数种组合,如下所示:8*15 = 120 = 7*16+1*8 = 5*16+3*8 = 4*16+5*8 = 3*16+7*8 = ...
因此只要仔细研究相应的编码,让8个15比特编码的字符和最终变换后的字符都是可见字符,就可以构造出两个完全不同的字符串输入,在经过微信小程序官方NodeJS国密算法库的初始化变换后,会变成同样的二进制串输入到SM3核心变换函数中,并最终得到同样的SM3哈希值!
JS的codePointAt函数返回的就是UTF16的码点值,利用上述方法,将任选的8个中文字符的二进制串(最高比特位为0)重新分割,使其也能够表示成其他中文字符(最高比特位需为1)与常见8比特可见字符的组合即可。这里我们随意构造了一组,其二进制串为:
100111000100111 100111000011001
100111000001010 100100000001001
100110000001011 100111000001101
100111010010000 100111001010001使用该函数的字符到二进制转换方式,原始字符串为:丧丙上䠉䰋不亐乑,重新对其二进制进行分割,如下:
1001110001001111 00111000 01100110
01110000 01010100 1000000010011001
1000000101110011 1000001101100111
01001000 01001110 01010001同样以该函数的二进制转换方式,字符串为:鱏8fpT肙腳荧HNQ。
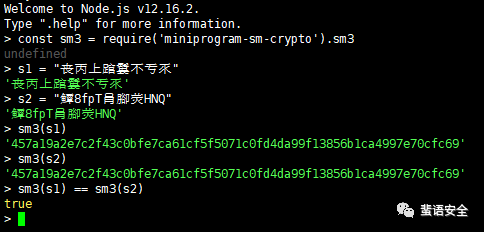
将这两个字符串传入该国密算法库的SM3函数,即可获得本文开头的碰撞结果。由此可知诸如这类的碰撞还可以构造很多。完整的POC.js代码如下:
const sm3 = require('miniprogram-sm-crypto').sm3
s1 = "丧丙上䠉䰋不亐乑"
console.log(s1)
s2 = "鱏8fpT肙腳荧HNQ"
console.log(s2)
h1 = sm3(s1)
console.log(h1)
h2 = sm3(s2)
console.log(h2)
console.log(h1 == h2)安装好nodejs环境后,可直接使用如下命令验证:
node POC.js使用该方法可以构造多组能够实现碰撞的字符串输入,甚至可能能够构造出两组有意义的字符串并形成SM3的碰撞!
修复方案
目前sm-crypto已经修复了该问题,需要将版本升级至目前最新的0.2.4。其修复思路是将输入的字符全部转成UTF-8编码的二进制串,再进行SM3计算。 事实上,国密SM3的规范仅仅约定了输入应当是二进制串或字节流,而非字符串。字符串如何转换成二进制串则需要依赖开发者选择不同的编码方式(如UTF-8,UTF-16等)。而该库SM3碰撞的本质原因正是由于其对字符串编码转换实现的错误导致。目前该库的修复方案是统一将字符转成UTF-8编码。这的确是一种方法但也对开发者失去了一些自由度,其实可以将SM3算法以二进制或字节数组为输入,同时提供不同编码方式的字符转字节数组的接口,供开发者使用,或由开发者自行实现字符转字节数组的方式。